Derivative of a CSV data set
I am trying to get the derivative of this CSV data set, and this is code I have so far I thought it would be similar to this matlab code:
dy=diff(y)./diff(x)
plot(x(2:end),dy)
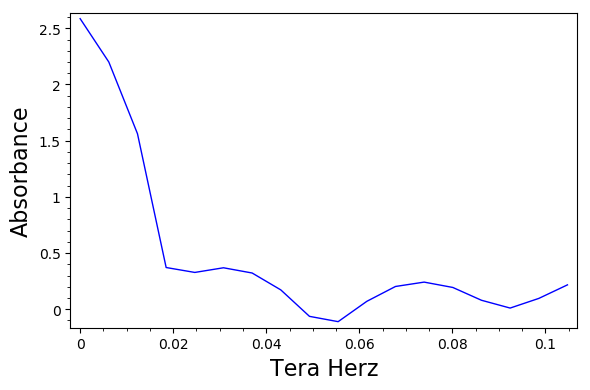
Data Set:
0,2.58612
0.00616025,2.20018
0.0123205,1.56186
0.0184807,0.371172
0.024641,0.327379
0.0308012,0.368863
0.0369615,0.322228
0.0431217,0.171899
0.049282,-0.0635003
0.0554422,-0.110747
0.0616025,0.0701394
0.0677627,0.202381
0.073923,0.241264
0.0800832,0.193697
0.0862434,0.0797016
0.0924037,0.0103144
0.0985639,0.096153
0.104724,0.216782
There's more data...a lot more This is my attempt at the code:
import csv
data = list( csv.reader(open('C:/images/TEST1.txt','rU')) )
data = map(lambda x: [float(x[0]),float(x[1])],data)
P = list_plot(data, plotjoined= True, color = 'blue', xmin = 0, xmax = 3)
TeraHertz = text('Tera Hertz', (1.5,-.9))
Absorbance = text('Absorbance', (0.8,5))
g = P + TeraHertz + Absorbance
g.show()
latex(g)
g.save('TeraHertzTEST1.pgf')
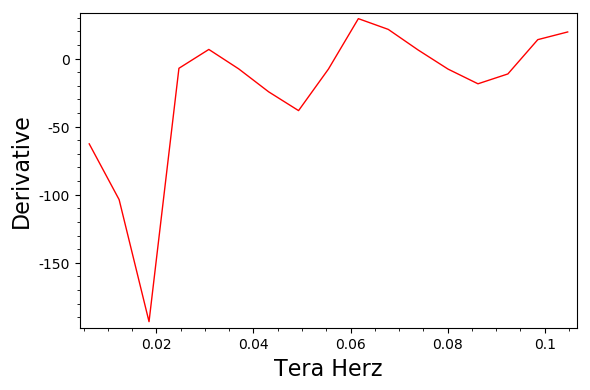
t=diff(x[1]).diff(x[0])
l = plot(x[0],t)
l.show()


If possible, please post a link to the csv data set. It might help come up with answers to the question.
@slelievre Ok I will, it keeps saying greater thaan 60 points to upload file....
@slelievre I entered as many data points there is just a lot more data.
What actually is the problem? Why didn't this work? If the data is very large you might also consider using numpy to load the data set:
import numpy as np; data = np.loadtxt('data.txt', delimiter=','). See loadtxt for more. For large data sets using Numpy will be both much faster than manually parsing strings returned by the standard Python csv module, and will be much, much more memory-efficient. Honestly, the SageMath documentation does not do enough to emphasize use of Numpy.I think that the problem was the lack of a pure Python equivalent of the Matlab
difffunction, which can be replaced with a list comprehension. Anyway, you are right, things are more easily and efficiently done with Numpy.