Is map_reduce working for parallel computing? How?

The following computation was done on a computer with 16 CPUs.
sage: seeds = [[]]
....: succ = lambda l: [l+[0], l+[1]] if len(l) <= 22 else []
....: S = RecursivelyEnumeratedSet(seeds, succ,structure='forest', enumeration='depth')
....: map_function = lambda x: 1
....: reduce_function = lambda x,y: x+y
....: reduce_init = 0
....: %time S.map_reduce(map_function, reduce_function, reduce_init)
....:
CPU times: user 15 ms, sys: 47 ms, total: 62 ms
Wall time: 58.4 s
16777215
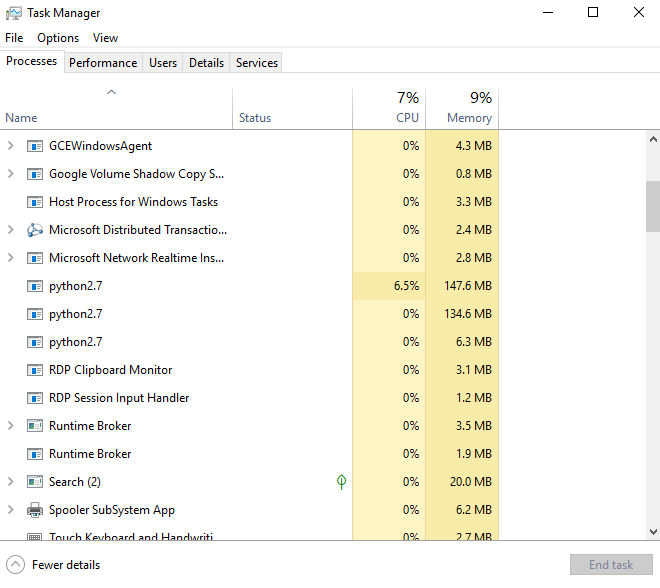
But it seems that the computation did not exploit the CPUs in parallel, as the following screenshot show.
Question: What's wrong? How to exploit the CPUs in parallel?
add a comment
